
Рефераты по авиации и космонавтике
Рефераты по административному праву
Рефераты по безопасности жизнедеятельности
Рефераты по арбитражному процессу
Рефераты по архитектуре
Рефераты по астрономии
Рефераты по банковскому делу
Рефераты по сексологии
Рефераты по информатике программированию
Рефераты по биологии
Рефераты по экономике
Рефераты по москвоведению
Рефераты по экологии
Краткое содержание произведений
Рефераты по физкультуре и спорту
Топики по английскому языку
Рефераты по математике
Рефераты по музыке
Остальные рефераты
Рефераты по биржевому делу
Рефераты по ботанике и сельскому хозяйству
Рефераты по бухгалтерскому учету и аудиту
Рефераты по валютным отношениям
Рефераты по ветеринарии
Рефераты для военной кафедры
Рефераты по географии
Рефераты по геодезии
Рефераты по геологии
Рефераты по геополитике
Рефераты по государству и праву
Рефераты по гражданскому праву и процессу
Рефераты по кредитованию
Рефераты по естествознанию
Рефераты по истории техники
Рефераты по журналистике
Рефераты по зоологии
Рефераты по инвестициям
Рефераты по информатике
Исторические личности
Рефераты по кибернетике
Рефераты по коммуникации и связи
Рефераты по косметологии
Рефераты по криминалистике
Рефераты по криминологии
Рефераты по науке и технике
Рефераты по кулинарии
Рефераты по культурологии
Курсовая работа: Проектирование системы передачи цифровых данных
Курсовая работа: Проектирование системы передачи цифровых данных
МИНИСТЕРСТВО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
ОМСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
Кафедра Автоматика и системы управления
Дисциплина Теория информационных систем
РАСЧЕТНО-ПОЯСНИТЕЛЬНАЯ ЗАПИСКА
К КУРСОВОМУ ПРОЕКТУ ПО ТЕМЕ
Проектирование системы передачи цифровых данных
Выполнил
студент группы И-229
Лаврухин А.А.
Омск 2004
УДК 621.398
РЕФЕРАТ
с. 31, илл. 4, табл. 1, источн. 5, прил. 3
ПОМЕХОУСТОЙЧИВОСТЬ, ЛИНИЯ СВЯЗИ, КОРРЕКТИРУЮЩИЙ КОД, КОДЕР, ДЕКОДЕР, МАНЧЕСТЕРСКИЙ КОД, ПРОПУСКНАЯ СПОСОБНОСТЬ
В курсовом проекте по заданной корректирующей способности выбран код, определены правила кодирования и декодирования; разработана схемотехническая и программная реализации кодера и декодера, выбран способ представления информации в канале связи, определена линия связи и её параметры, рассмотрены вопросы практической реализации.
СОДЕРЖАНИЕ
Введение
Задание
1. Теоретическая часть
1.1 Элементы теории кодирования
1.1.1 Основные понятия и определения
1.1.2 Представление кодов
1.1.3 Классификация кодов
1.1.4 Построение кода с заданной коррекцией
1.1.5 Коды Хэмминга
1.1.6 Циклические коды
1.2 Кабельные системы на основе медных линий
2. Практическая часть
2.1 Выбор корректирующего кода
2.2 Схемотехническая и программная реализация кодера и декодера
2.3. Выбор канала связи и модуляции
Заключение
Список использованных источников
Приложение 1
ВВЕДЕНИЕ
В настоящее время очень развиты различные системы передачи данных, разработаны основные стандарты, на основе которых строятся реальные системы. В настоящей работе была осуществлена попытка спроектировать систему связи, основанную на современных представлениях о кодировании. Кодирование применяется в целях приобретения сигналом, передаваемом по линии связи, избыточности и, благодаря этому, информационной помехозащищённости.
В работе произведён анализ основных известных методов кодирования и введён новый метод. Рассмотрены вопросы практической реализации, что позволило провести сравнение с другими методами кодирования и передачи сигналов.
ЗАДАНИЕ
Система передачи данных должна обеспечивать передачу информации со скоростью 10 Мб/с. Корректирующий код для обеспечения помехоустойчивости должен обеспечивать обнаружение трёх ошибок в восьми информационных разрядах.
В курсовой работе необходимо:
1. Произвести выбор корректирующего кода по заданному количеству информационных разрядов и количеству исправляемых ошибок (выбрать вид кода, привести примеры кодирования и декодирования).
2. Разработать схемотехническую реализацию кодера и декодера.
3. Выбрать способ представления информации в канале передачи (выбирается способ модуляции и кодирования).
4. Сформулировать технические требования для возможной практической реализации.
1. ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
1.1 ЭЛЕМЕНТЫ ТЕОРИИ КОДИРОВАНИЯ
1.1.1 Основные понятия и определения
Алфавит – произвольный конечный, фиксированный набор символов (букв, знаков и др.), используемый в данной знаковой системе или языке. Первичный алфавит – алфавит, с помощью которого записывается передаваемое сообщение. Вторичный алфавит – алфавит, с помощью которого сообщение преобразуется в код. Таким образом, код – это совокупность символов вторичного алфавита, однозначно представляющая передаваемое сообщение. Процесс преобразования символов первого алфавита в символы (сигналы) второго алфавита называется процессом кодирования информации. Процесс восстановления содержания сообщения по данному коду называется декодированием. Последовательность символов, которая в процессе кодирования присваивается каждому из множества передаваемых сообщений, называется кодовым словом. Коды, в которых сообщения представлены равными по количеству символов кодовыми словами, называются равномерными кодами, в противном случае – неравномерными. Количество символов в кодовом слове называется длиной слова (длиной кода). В общем случае число возможных сообщений, которые можно закодировать комбинацией символов вторичного алфавита определяется уравнением:
N=qn,(1)
где N – число возможных сообщений, q – основание кода или число признаков кодовой комбинации, n – длина кодового слова.
Если q=2, то коды называются двоичными, q=3 – троичными и т.д.
Передачу кодовых комбинаций можно осуществить последовательно во времени или параллельно. В последнем случае передача должна осуществляться по нескольким параллельным линиям (каналам) связи.
Количество комбинаций кодовых сообщений определяется выбранным методом построения кода, числом качественных признаков (алфавитом) и числом элементов кода (длиной кода).
1.1.2 Представление кодов
Для построения кодов используются методы теории чисел, алгебры, комбинаторики, теории вероятности и т.д. Коды могут быть представлены в виде формул, таблиц, графов, геометрически и т.д.
Кодовые комбинации можно представить в виде полиномов.
Любое число в любой системе счисления с основанием x может быть представлено в виде суммы ряда. Для целых чисел эта сумма имеет вид:
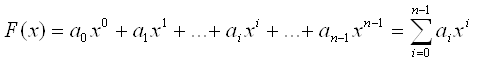 ,(2)
,(2)
где x – основание системы счисления, a – символ системы счисления, i – показатель степени основания системы счисления и индекс позиции i-го члена ряда.
Иначе коды представляются в виде матриц. Равномерные n‑значные x‑е коды можно представить в виде матрицы, содержащей xn строк и n столбцов. Если исключить нулевые комбинации кода, то число строк будет равно xn – 1.
Особенностью такого способа представления кода является то, что комбинация кода, полученная в результате сложения произвольно взятых строк матрицы также является одной из комбинаций данного кода т.к. в матрице записаны все xn – 1 кодовые комбинации n‑значного кода.
Если суммировать строки матрицы по mod x, то можно получить нулевую строку. После её исключения получится новая матрица с меньшим числом строк, в которой тоже можно определить нулевую строку и исключить её и т.д. до тех пор пока строки станут линейно независимы, т.е. сложение по mod x не даёт нулевой строки. Полученная в результате матрица будет диагональной и единичной т.е. главная диагональ матрицы состоит из единиц, а остальные равны 0. Умножение произвольной матрицы на диагональную единичную не меняет её значений. Если строки этой матрицы складывать по mod x, то можно восстановить все комбинации n‑значного кода. Поэтому такие матрицы называют образующими или определяющими. Определяющая матрица называется транспонированной, если главная диагональ слева вверх направо.
1.1.3 Классификация кодов
Всё множество известных в настоящее время кодов условно делят на два направления: непомехозащищённые и помехозащищённые.
К первому направлению относятся следующие коды:
Двоичный код на все сочетания – кодовые комбинации этого кода соответствуют записи натурального ряда чисел в двоичной системе счисления. Общее число комбинаций этого кода равно
N = 2n ,
где N – общее число комбинаций кода; n – длина кода.
Единично‑десятичный код. Каждому разряду десятичного числа соответствует определённое количество единиц. Разряды отделяются интервалами. Этот код неравномерный, но может быть преобразован в равномерный, если слева в каждом разряде дописать недостающие единицы нулями до 10 знаков.
Двоично‑десятичный код. Каждый разряд десятичного числа записывается в виде комбинации кодов. Существует несколько видов двоично‑десятичных кодов: код с весовыми коэффициентами 8.4.2.1, код с весовыми кэффициентами 2.4.2.1 (код Айкена)
Число‑импульсный код – единичный (унитарный), кодовые комбинации различаются числом единиц.
Код Морзе – относится к неравномерным кодам. Кодовые комбинации имеют разную длительность: точка – 1, тире – 111, интервал между точкой и тире – 0, интервал между комбинациями (буквами) – 000.
Код Бордо – равномерный пятиэлементный телеграфный код. Максимальное число комбинаций N = 25 = 32.
Код Грея (рефлексивный, отражённый). Две соседние комбинации отличаются только в соседних разрядах: Для преобразования обычного двоичного кода в код Грея необходимо сложить данную комбинацию с самой по mod 2, но сдвинутой вправо на один разряд.
Помехозащищённые (помехоустойчивые или корректирующие) коды предназначены для обнаружения и исправления ошибок. В теореме К. Шеннона утверждается, что вероятность ошибок для дискретного канала с помехами может быть сведена к минимуму с помощью выбора соответствующего способа кодирования. В двоичных кодах каждый разряд может принимать значения 0 или 1. Количество единиц в кодовой комбинации называют весом кодовой комбинации и обозначают w. Например, кодовая комбинация 100101100 имеет длину (значность) 9 и вес w = 4. Степень отличия двух кодовых комбинаций называется кодовым расстоянием или расстоянием Хемминга, оно обозначается как d. Кодовое расстояние – это минимальное расстояние между кодовыми комбинациями, определяемое количеством (числом) отличающихся позиций или символов в кодовых комбинациях. Для вычисления кодовых расстояний используется сложение по mod 2.
При воздействии помех в кодовой комбинации в одном или нескольких разрядах возможна трансформация 0 в 1 и 1 в 0 и получается наложенная комбинация. Ошибки, полученные в разряде кодовой комбинации, называют однократными. При 2‑х, 3‑х и т.д. разрядах – двукратными, трёхкратными и т.д.
Для определения мест ошибок в кодовой комбинации вводится понятие вектора ошибок. Вектор ошибок n‑разрядного кода – это n‑разрядная комбинация, единицы в которой указывают положение искажённых символов кодовой комбинации.
Вес вектора ошибки we характеризует кратность ошибки. Сумма по модулю 2 для искажённой кодовой комбинации и вектора ошибки равна исходной неискажённой комбинации.
Помехоустойчивость кодирования обеспечивается за счёт введения избыточности в кодовые комбинации. Это значит, что не все n символов кодовой комбинации используются для кодирования информации, а только какая их часть k<n. Следовательно, из всех возможных комбинаций N0 = 2n для кодирования используется Nk = 2k комбинаций, т.е. всё множество возможных кодовых комбинаций делится на две группы:
Группа Nk = 2k – разрешённых комбинаций.
Группа (N0 – Nk) = 2n – 2k – запрещённых комбинаций.
Если на приёмной стороне получена разрешённая комбинация, то считается, что искажений нет, иначе принятая комбинация искажена.
В общем случае каждая из Nk разрешённых комбинаций может трансформироваться в любую из N0 возможных комбинаций, т.е. всех возможных комбинаций может быть Nk*N0, Nk(Nk–1) переходы одних разрешённых комбинаций в другие разрешённые и Nk(N0–Nk) переходов в запрещённые комбинации.
Таким образом, не все искажения могут быть обнаружены, а только те, для которых определяются следующим уравнением:
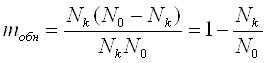 .(3)
.(3)
Для построения кода, обеспечивающего не только обнаружения ошибок, но и исправление ошибок. Множество запрещённых кодовых комбинаций разбивается на Nk непересекающихся подмножеств Nk, каждому из которых ставится в соответствие одна из разрешённых комбинаций. В этом случае, если принятая запрещённая комбинация принадлежит подмножеству Mi, то считается, что передана комбинация Аi и ошибка будет исправлена. Т.о. ошибка исправляется в (N0-Nk) случаях, равных количеству запрещённых комбинаций от общего числа обнаруженных ошибочных комбинаций определяется уравнением:
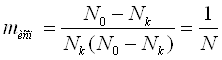 .(4)
.(4)
Выбор способа разбиения на подмножества определяется типом ошибок. Допустим, необходимо построить код, обнаруживающий все ошибки кратностью t и меньше. Это значит, что из множества всех возможных комбинаций N0 необходимо выбрать Nk разрешённых комбинаций так, чтобы любая из них в сумме по модулю два с любым вектором ошибок E с весом we£t не была равна никакой другой разрешённой комбинации. Для этого необходимо, чтобы кодовое расстояние удовлетворяло равенству:
dmin ³ t + 1, (5)
где dmin – наименьшее расстояние Хэмминга.
1.1.4 Построение кода с заданной коррекцией
При рассмотрении корректирующих кодов предполагалось, что его длина n задана, а повышение корректирующей способности кода достигалось за счёт уменьшения множества Nk разрешённых комбинаций при неизменном n или уменьшении информационных символов k. На практике коды строятся в обратном порядке: вначале выбирается количество информационных символов, а затем обеспечивается необходимая корректирующая способность кода за счёт добавления избыточных символов.
Если задано число корректирующих разрядов k (), а всего в коде n разрядов, то граница Хемминга для исправления l ошибок определяется выражением:
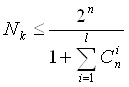 (6)
(6)
Все корректирующие коды можно разделить на два основных класса: непрерывные (рекуррентные) и блочные. В непрерывных кодах процесс кодирования и декодирование имеет непрерывный характер. Каждый избыточный символ (проверочный) формируется по двум или нескольким информационным символам. Проверочные символы размещаются в определённом порядке между информационными символами исходной последовательности.
В блочных кодах каждому сообщению (или элементу сообщения) соответствует кодовая комбинация из n символов, которая называется блоком. Блоки кодируются и декодируются раздельно. Блочные коды могут быть равномерными, если n – постоянно, и неравномерными, если n – непостоянно. Как непрерывные, так и блочные коды в зависимости от методов размещения проверочных символов могут быть разделимыми и неразделимыми. В разделимых кодах одни символы являются информационными, а другие проверочными и служат для обнаружения и исправления ошибок. Информационные и проверочные символы занимают во всех комбинациях одни и те же позиции.
Разделимые блочные коды называют n,k‑кодами, где n – значность кода, к – число информационных символов. Разделимые блочные коды делятся на несистематические и систематические. В несистематических кодах проверочные символы представляют суммы подблоков длиной l, на которые разделена последовательность информационных символов. Такой код может обнаружить серийные ошибки с длиной серии не более l. В несистематических или линейных кодах проверочные символы определяются в результате линейных операций над определёнными информационными символами. Для двоичных кодов каждый проверочный символ выбирается таким, чтобы его сумма по mod2 с определёнными информационными символами стала равной 0. При декодировании производится проверка на четность определённых групп символов, поэтому также коды ещё называют – коды с проверкой на четность.
1.1.5 Коды Хэмминга
Двоичный код Хэмминга содержит k информационных символов и p=n‑k избыточных символов. Избыточная часть кода строится так, чтобы при декодировании можно было указать номер позиции, в которой произошла ошибка. Это достигается путём многократной проверки принятой комбинации на четность. Количество проверок равно количеству избыточных символов Р. При каждой проверке получают двоичный контрольный символ. Если результат проверки даёт чётное число единиц, то контрольному символу присваивается 0, иначе –1. В результате всех проверок получается p‑разрядное двоичное число, указывающее номер искажённого символа. Для исправления ошибки достаточно проинвертировать данный символ.
Необходимое количество проверочных символов p (или значность кода n) определяется по формуле:
Nk £ 2n/(1+n)(7)
Значения проверочных символов и номера их позиций устанавливаются одновременно с выбором контролируемых групп кодовой комбинации.
При первой проверке получают цифру младшего разряда контрольного числа, указывающего номер искаженного символа. Если в результате проверки младший разряд контрольного числа равен 1, то один из символов данной группы искажён.
Для упрощения операций кодирования и декодирования рекомендуется размещать проверочные символы так, чтобы каждый входил в минимальное число проверяемых групп, то есть размещать контрольные символы на позициях, номера которых встречаются только в одной из проверочных групп: 1, 2, 4, 8.(Таблица 2). Следовательно в кодовой комбинации символы а1, а2, а4, а8 . . . должны быть проверочными, а символы а3, а5, а6, а7, а9, и т. д.- информационными.
Так как значения информационных символов определяются заранее, то значения проверочных символов должны быть такими, чтобы сумма единиц в каждой проверочной группе была чётным числом.
1.1.6 Циклические коды
Циклические коды являются наиболее простыми и эффективными для обнаружения и исправления независимых и серийных ошибок. Основным свойством циклических кодов является то, что каждая кодовая комбинация может быть получена путём циклической перестановки символов комбинации, принадлежащей данному коду, то есть если кодовый вектор V=(a0,a1,a2, . . ., an-2) принадлежит циклическому коду, то и вектор V1 = (an‑1, a0, a1, a2, . . ., an-2) также ему принадлежит. Циклические коды записываются в виде полиномов.
Идея построения циклических кодов базируется на использовании неприводимых многочленов. Неприводимым называется многочлен, который не может быть представлен в виде произведения многочленов низших степеней, т.е. такой многочлен делиться только на самого себя или на единицу и не делиться ни на какой другой многочлен. На такой многочлен делиться без остатка двучлен xn+1. Неприводимые многочлены в теории циклических кодов играют роль образующих полиномов.
Для построения циклического кода, комбинация простого k-значного кода Q(x) умножается на одночлен xr, затем делится на образующий полином P(x), степень которого равна r. В результате умножения Q(x) на xr степень каждого одночлена, входящего в Q(x), повышается на r. При делении произведения xrQ(x) на образующий полином получается частное C(x) такой же степени, как и Q(x). Частное C(x) имеет такую же степень, как и кодовая комбинация Q(x) простого кода, поэтому C(x) является кодовой комбинацией этого же простого k-значного кода. Наибольшее число разрядов остатка R(x) не превышает числа r. Окончательное выражение для кода:
F(x) = C(x) P(x) = Q(x) xr + R(x). (8)
1.2 КАБЕЛЬНЫЕ СИСТЕМЫ НА ОСНОВЕ МЕДНЫХ ЛИНИЙ
В настоящее время для передачи данных часто используются 4-парные кабели из одножильных медных проводников диаметром 0,51 мм (стандарт 24AWG). Витая пара - пара скрученных проводов с соблюдением числа скруток на единицу длины. Один из проводов скрученной пары используется как сигнальный, второй - как сигнальная земля. Тем самым обеспечивается экранирование от помех. Различные кабели имеют от 6¸63 скруток на метр. Обычные значения от 36¸58 скруток на метр. Для улучшения параметров кабеля во всем диапазоне заданных спецификацией частот параметры скручивания (шаг скрутки) каждой пары несколько отличаются. Все 4 пары кабеля помещаются в пластиковую оболочку. В некоторых случаях между оболочкой и проводниками помешается экран из тонкой металлической фольги (кабель STP).
Табл. 1
Электрические спецификации кабелей категории 3, 4 и 5
| Параметр | Категория 3 | Категория 4 | Категория 5 |
| Число пар | 4 | 4 | 4 |
| Импеданс | 100 Ом ±15% | 100 Ом ±15% | 100 Ом ±15% |
|
Максимальное затухание (dB на 100 м, при 20 C) |
4 МГц: 5.6 10 МГц: 9.8 16 МГц: 13.1 |
4 МГц: 4.3 10 МГц: 7.2 16 МГц: 8.9 |
16 МГц: 8.2 31 МГц: 11.7 100 МГц: 22 |
|
Переходное затухание (NEXT), не менее dB |
4 МГц: 32 10 МГц: 26 16 МГц: 23 |
4 МГц: 47 10 МГц: 41 16 МГц: 38 |
16 МГц: 44 31 МГц: 39 100 МГц: 32 |
2. ПРАКТИЧЕСКАЯ ЧАСТЬ
2.1. ВЫБОР КОРРЕКТИРУЮЩЕГО КОДА
Код Хемминга
Зная, что на 8 информационных разрядов может приходиться до трёх ошибок, определим, какой потребуется код Хемминга для шестнадцати информационных разрядов. Количество обнаруживаемых ошибок составит 6. Тогда согласно (6),
![]() ,
,
где кодовое
расстояние ![]() ,
,
![]() , можно
найти
, можно
найти ![]() .
Длина кода составит
.
Длина кода составит ![]() . Таким образом, получится код
Хемминга (28,16). Как видно, этот код не очень эффективный, т. к.
количество контрольных разрядов близко к количеству информационных.
. Таким образом, получится код
Хемминга (28,16). Как видно, этот код не очень эффективный, т. к.
количество контрольных разрядов близко к количеству информационных.
Код БЧХ
Рассмотрим
код БЧХ с общим числом разрядов 31. Как было определено выше, требуется
построить код для ![]() . По таблице кодов БЧХ [2] находим
образующий полином:
. По таблице кодов БЧХ [2] находим
образующий полином:
![]()
Получили код БЧХ (31,16). Как видно, этот код ещё менее эффективен, чем соответствующий код Хемминга.
Построение кода
Построим свой код. Забегая вперёд, отметим, что для синхронного приёма кода требуется либо отдельно посылать синхроимпульсы, либо использовать самосинхронизирующийся код. В качестве такового можно использовать манчестерский код. Для лучшего использования возможностей витой пары (именно её мы будем использовать) можно передавать сигнал не по одной паре проводов, а по всем четырём. Причём по одной паре проводов будет передаваться манчестерский код, что обеспечит синхронизацию источника и приёмника, а по трём другим парам проводов пойдёт сигнал, синхронный с сигналом первой линии. По этим трём линиям будем передавать трёхуровневый сигнал. Поскольку манчестерское кодирование увеличит вдвое частоту, будем передавать трёхуровневый сигнал также с удвоенной частотой.
Итак, по одной паре проводов за один такт возможна передача одного из двух видов импульсов (рис. 1), что значит 1 бит за такт. По трём другим парам возможна передача одного из девяти видов импульсов (рис. 2). Из этих импульсов будем использовать только 8, т.е. за такт можно передать 3 бита.
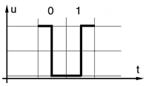
Рис. 1
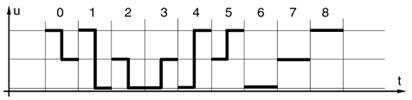
Рис. 2
За один такт по четырём парам проводов возможна передача 1+3+3+3=10 бит. Будем рассматривать передаваемые 10 бит за такт как один символ. Это значит, при кодировании будем оперировать 10-битными символами, т.е. двоично-1024-ричным кодом.
Для передачи информационного кода по ЛС требуется:
1. Преобразовать исходный двоичный код в двоично-1024-ричный. Для этого достаточно разбить код на группы по 10 бит.
2. Найти контрольные (проверочные) символы (операция кодирования).
3. Добавить контрольные разряды к информационным и смодулировать сигнал для отправления по ЛС (операция модуляции).
4. После прохождения сигнала через ЛС, он должен быть демодулирован.
5. Полученный код проверяется на наличие ошибок.
6. При отсутствии ошибок код преобразуется в двоичный для последующего использования.
Если задан двоичный 88-разрядный код (11 байт), то при записи его в двоично-1024-ричном виде, получится 9 символов (8 символов по 10 бит и 1 символ из 8 бит). Т.е. исходные 88 двоичных разряда разбиваются на 9 групп по 10 разрядов. Каждую группу назовём 1024-ричным символом.
Код будет
обнаруживать 3 ошибки (на 9 двоично-1024-ричных разрядов), т.е. кодовое расстояние
![]() .
.
Сначала определим правило нахождения контрольных символов. Если записать в виде таблицы информационные разряды, то можно заметить, что три контрольных символа рассчитываются по соответствующим строкам (суммируются символы по модулю 32), три других – по строкам и один – по первым шести контрольным.
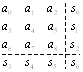
Рис. 2
Иначе говоря,
![]() ,
, ![]() ,
, ![]() ,(9)
,(9)
![]() ,
, ![]() ,
, ![]() ,
, ![]() .
.
Построим матрицу кодирования (образующую матрицу). Матрица кодирования будет содержать 9 строк (по количеству разрядов), левая часть матрицы содержит единичную матрицу [2]. Правая часть задаёт контрольные разряды:
 .(10)
.(10)
Перемножая вектор информационного кода на эту матрицу, можно получить вектор, в котором информационные и контрольные разряды разделены, число контрольных разрядов равно 7:
![]() .
.
Естественно, все операции должны выполняться по модулю 1024. Для проверки принятого кода на отсутствие ошибок требуется вектор умножить на проверочную матрицу. Проверочная матрица будет иметь следующий вид:
 ,(11)
,(11)
где левая часть матрицы содержит транспонированную правую часть образующей матрицы. Проверка правильности кода примет вид:
![]() .
.
Таким образом, код состоит из 20 байт, из которых 9 контрольных и 11 информационных. Код обнаруживает до трёх ошибок, причём не в отдельных двоичных разрядах, а в символах по 10 разрядов.
Матрицы (10) и (11) описывают код (160,88). Нельзя сказать, что код получился оптимальнее, чем код Хемминга или БЧХ (по скорости кодирования), однако его преимущество – более высокая скорость передачи, за счёт усложнения формы сигнала и более полного использования линии связи. Недостаток полученного кода – сравнительно сложная схемная реализация.
Примеры кодирования-декодирования
Для примера рассмотрим кодирование последовательности
92 8E AA 9B A2 A5 9A 55 4B D2 B4.
Эта последовательность в двоично-1024-ричном виде будет выглядеть так:
1001001010.0011101010.1010100110.1110100010.1010010110.0110100101.
0101010010.1111010010.10110100.
Для выравнивания, добавим в конец ещё два нулевых бита.
Информационный вектор K= [1001001010 0011101010 1010100110 1110100010 1010010110 0110100101 0101010010 1111010010 1011010000]
умножаем на образующую матрицу (9):

Получили закодированную последовательность: к информационной части прибавились 7 контрольных символов (70 бит).
Допустим, при прохождении через ЛС, сигнал не исказился. Проведём декодирование:

Нулевой синдром свидетельствует об отсутствии ошибки.
Допустим теперь, что возникли три ошибки (во втором, девятом, тринадцатом символах):

Синдром ненулевой, ошибка обнаружена.
2.2 СХЕМОТЕХНИЧЕСКАЯ И ПРОГРАММНАЯ РЕАЛИЗАЦИЯ КОДЕРА И ДЕКОДЕРА
Для схемной реализации кодера и декодера потребуются 10-разрядные сумматоры. Схемы кодера и декодера приведены в приложении 1. Кодер позволяет получить контрольные символы по информационным. Схема составлена в полном соответствии с выражениями (9) и матрицей (10). Декодер соответствует матрице (11).
В приложении 2 приведена схема всей системы передачи данных. Исходный код (11 байт) подаётся на регистр REG1. Это можно сделать, например, трёхкратной передачей по 32 разряда (4 байта). Регистр может быть также буфером, необходимым для синхронной передачи, независимой от работы программного обеспечения. Регистр с рабочей частотой выставляет на выходные 10-разрядные шины (9 таких шин) данные. При прохождении их через кодер К, на его выходе появляются контрольные разряды, которые соединяются с информационными разрядами, прошедшими через элемент задержки Т. На выходе элементов Т и К появляются 20 байт помехоустойчивого кода, который по 16 10-разрядным шинам поступает на регистр REG2. Этот регистр преобразует параллельный код в последовательный для передачи по линии. Код, поступивший по 16 шинам, будет отправлен за 16 тактов (передачи). Далее следует модулятор М, преобразующий 10 бит кода, пришедшего с REG2, в сигнал, отправляемый по четырём линиям (один двухуровневый и три трёхуровневых). Сигналы отправляются синхронно.
Передающая часть с помощью демодулятора ДМ преобразует физический сигнал в 10 бит кода. 10-битные слова записываются в регистр REG3 (для преобразования в параллельный код). При накоплении нужного количества разрядов, данные по 16 10-разрядным шинам поступают на декодер ДК. После декодирования синдром ошибки с выхода ДК поступает на ключ Кл (в общем случае это может быть какое-либо решающее и управляющее устройство). При отсутствии ошибки код поступает на регистр REG4 (буфер), откуда снимается последовательно по 32 разряда (4 байта).
Схемотехническая реализация на бинарных элементах – один из способов кодирования-декодирования. Можно программно их реализовать. В приложении 3 помещены листинги программ кодера и декодера (принципиальная реализация кодирования-декодирования).
В данном случае программная реализация позволяет снизить стоимость системы, однако дополнительно загружает центральный процессор.
2.3 ВЫБОР КАНАЛА СВЯЗИ И МОДУЛЯЦИИ
Вид огибающей для кода был описан выше. Для одной пары проводов это манчестерское кодирование, для других трёх – сигнал, составленный из импульсов, изображённых на рис. 2. Будем использовать импульсы, изображённые на рис. 3.
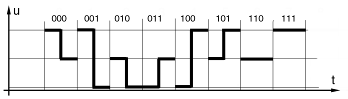
Рис. 3
Рассмотрим вид огибающей для вышерассмотренного примера. Для удобства полученный код запишем в таком виде:
1.001.001.010…0.011.101.010…1.010.100.110…1.110.100.010
1.010.010.110…0.110.100.101…0.101.010.010…1.111.010.010
1.011.010.000…0.111.011.010…1.111.011.101…1.111.110.100
1.100.111.110…1.101.010.010…1.100.011.011…1.101.010.110
Сигнал, проходяший синхронно по четырём парам проводников, изображен на рис. 4.
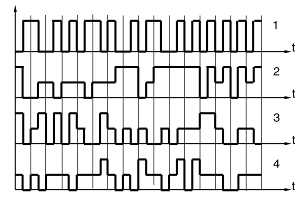
Рис. 4
Уже было сказано, что в качестве линии связи выбрана витая пара. Кабели на витых парах позволяют использовать большое число пар в кабеле (до 250), передавать данные на частотах 16–100 МГц, компенсировать наводки (возникающие за счёт вихревых токов), они обладают невысокой стоимостью. Однако к недостаткам можно причислить малую помехозащищённость, невозможность использования длинных кабелей (больше 1000 м).
Поскольку за 20 тактов передаётся 11 байт полезной информации, то за 1 такт – 4.4 бита. Поэтому если, например, удвоенная частота (для манчестерского кода) будет составлять 50 МГц, то частота тактов составит 25 МГц и скорость передачи достигнет 25*4.4=110 Мбит/с. Т.е. поставленная задача даже перевыполнена. Для линии связи будем использовать кабель категории 5. Как видно из табл. 1, на частоте около 50 МГц затухание составит около 15 дБ, т.е. на каждые 100 м линии сигнал будет затухать в 5,5 раз. Чтобы приёмник распознал сигнал, линия не должна быть длиннее 120–150 м (тогда сигнал затухнет в ≈ 15 раз).
Для правильного определения границ передаваемого сообщения необходимо обеспечить синхронизацию передатчика и приёмника. В системе, рассматриваемой в данной работе, целесообразно использовать старт-стоповые символы, передаваемые до и после основного сообщения. Для этого можно использовать неиспользованные комбинации импульсов (номер 8 на рис. 2). Поскольку приём отдельных символов подразумевается синхронным благодаря манчестерскому коду, передаваемому по первой паре проводов, старт-стоповые символы можно передавать достаточно редко (в начале и в конце пакетов длиной около нескольких сотен байт). Синхронизация будет называться фреймовой (блочной).
В качестве вида модуляции можно выбрать амплитудную модуляцию. Это обеспечивает небольшое искажение сигнала на выходе линии связи благодаря не очень большой ширине спектра получающегося сигнала.
ЗАКЛЮЧЕНИЕ
В ходе работы удалось составить помехозащищённый код (160,88). Информационная скорость (отношение числа информационных разрядов к общему) составляет 0,55, что близко к характеристикам других кодов. Данный код может передавать большое количество информации (длинную последовательность) в одном пакете, что достигается параллельной передачей данных по четырём линиям (парам проводников), из которых состоит витая пара, выбранная в качестве линии передачи. По одной паре проводников передаётся манчестерский код, что обеспечивает синхронность приёма, однако возникают жёсткие требования к синхронизации между отдельными парами в кабеле, поскольку синхронизация остальных пар проводов осуществляется по первой паре.
Такое использование линии связи несколько усложняет практическую реализацию системы по сравнению с использованием обычных кодов (например, полиномиальных) и передачей по независимым каналам. Однако такое небольшое усложнение окупается возрастанием на порядок скорости передачи.
СПИСОК ИСПОЛЬЗОВАНЫХ ИСТОЧНИКОВ
1. Буга Н.Н. Основы теории связи и передачи данных, – М.: ЛВИКА им. Можайского. – 1970.
2. Кларк Дж., Кейн Дж. Кодирование с исправлением ошибок в системах цифровой связи. – М.: Радио и связь. – 1987.
3. Тутевич В.Н. Телемеханика. – М: Высшая школа, 1985. – 423 с.
4. Цымбал В.П. Теория информации и кодирование. – Киев: «Вища школа». –1992.
5. Шувалов В.П., Захарченко Н.В., Шварцман В.О. Передача дискретных сообщений/ под ред. Шувалова В.П. – М.: Радио и связь. – 1990.
ПРИЛОЖЕНИЕ 1
Программная реализация кодера
// Реализация кодера на языке С
// a0..a8 – информационные символы
// s0..s6 – контрольные символы
void coder(int a0, int a1, int a2, int a3,
int a4, int a5, int a6, int a7, int a8)
{
int s0,s1,s2,s3,s4,s5,s6;
s0=(0x3FF)&(a0+a1+a2);
s1=(0x3FF)&(a3+a4+a5);
s2=(0x3FF)&(a6+a7+a8);
s3=(0x3FF)&(a0+a3+a6);
s4=(0x3FF)&(a1+a4+a7);
s5=(0x3FF)&(a2+a5+a8);
s6=(0x3FF)&(s0+s1+s2+s3+s4+s5);
// передача контрольных разрядов
// . . . . .
}
Программная реализация декодера
// Реализация декодера на языке С
// a0..a8 – информационные символы
// s0..s6 – контрольные символы
// k – синдром ошибки
int decoder(int a0, int a1, int a2, int a3,
int a4, int a5, int a6, int a7, int a8,
int s0, int s1, int s2, int s3, int s4, int s5, int s6)
{
int k0,k1,k2,k3,k4,k5,k6,k;
k0=(0x3FF)&(a0+a1+a2-s0);
k1=(0x3FF)&(a3+a4+a5-s1);
k2=(0x3FF)&(a6+a7+a8-s2);
k3=(0x3FF)&(a0+a3+a6-s3);
k4=(0x3FF)&(a1+a4+a7-s4);
k5=(0x3FF)&(a2+a5+a8-s5);
k6=(0x3FF)&(2*(a0+a1+a2+a3+a4+a5+a6+a7+a8)-s6);
k=k0&k1&k2&k3&k4&k5&k6;
return k;
}