
Рефераты по авиации и космонавтике
Рефераты по административному праву
Рефераты по безопасности жизнедеятельности
Рефераты по арбитражному процессу
Рефераты по архитектуре
Рефераты по астрономии
Рефераты по банковскому делу
Рефераты по сексологии
Рефераты по информатике программированию
Рефераты по биологии
Рефераты по экономике
Рефераты по москвоведению
Рефераты по экологии
Краткое содержание произведений
Рефераты по физкультуре и спорту
Топики по английскому языку
Рефераты по математике
Рефераты по музыке
Остальные рефераты
Рефераты по биржевому делу
Рефераты по ботанике и сельскому хозяйству
Рефераты по бухгалтерскому учету и аудиту
Рефераты по валютным отношениям
Рефераты по ветеринарии
Рефераты для военной кафедры
Рефераты по географии
Рефераты по геодезии
Рефераты по геологии
Рефераты по геополитике
Рефераты по государству и праву
Рефераты по гражданскому праву и процессу
Рефераты по кредитованию
Рефераты по естествознанию
Рефераты по истории техники
Рефераты по журналистике
Рефераты по зоологии
Рефераты по инвестициям
Рефераты по информатике
Исторические личности
Рефераты по кибернетике
Рефераты по коммуникации и связи
Рефераты по косметологии
Рефераты по криминалистике
Рефераты по криминологии
Рефераты по науке и технике
Рефераты по кулинарии
Рефераты по культурологии
Контрольная работа: Расчет показателей эконометрики
Контрольная работа: Расчет показателей эконометрики
Содержание
Задача 1
Решение
Задача 2
Решение
Задача 3
Решение
Задача 4
Решение
Задача 5
Решение
Список используемой литературы
Приложение
Задача 1
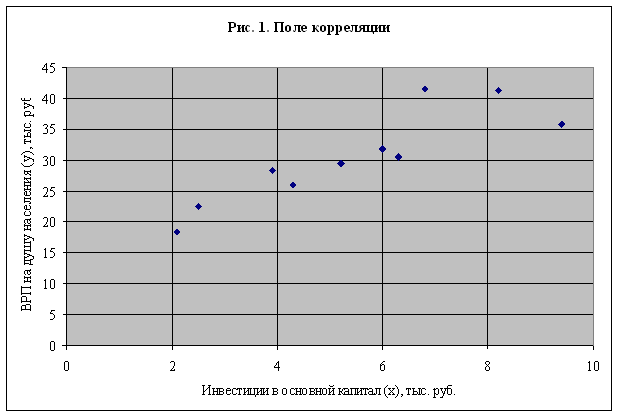
По регионам страны изучается зависимость ВРП на душу населения (y тыс. руб.) от инвестиций в основной капитал (x - тыс. руб.):
| № региона | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| x, тыс. руб. | 9,4 | 2,5 | 3,9 | 4,3 | 2,1 | 6,0 | 6,3 | 5,2 | 6,8 | 8,2 |
| y, тыс. руб. | 35,8 | 22,5 | 28,3 | 26,0 | 18,4 | 31,8 | 30,5 | 29,5 | 41,5 | 41,3 |
Задание
1. Постройте поле корреляции, характеризующее зависимость ВРП на душу населения от размера инвестиций в основной капитал.
2. Определите параметры уравнения парной линейной регрессии. Дайте интерпретацию коэффициента регрессии и знака при свободном члене уравнения.
3. Рассчитайте линейный коэффициент корреляции и поясните его смысл. Определите коэффициент детерминации и дайте его интерпретацию.
4. Найдите среднюю ошибку аппроксимации.
5. Рассчитайте стандартную ошибку регрессии.
6. С вероятностью 0,95 оцените статистическую значимость уравнения регрессии в целом, а также его параметров. Сделайте вывод.
7. С вероятностью 0,95 постройте доверительный интервал ожидаемого значения ВРП на душу населения в предложении, что инвестиции в основной капитал составят 80% от максимального значения. Сделайте вывод.
Решение
1. Построение поля корреляции производится по исходным данным о парах значений ВРП на душу населения и инвестиций в основной капитал.
2. Оценка параметров уравнения парной линейной регрессии производится обычным методом наименьших квадратов (МНК).
Для расчета параметров a и b линейной регрессии y = a + b*x решаем систему нормальных уравнений относительно a и b:
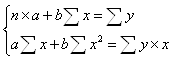
По исходным данным (табл. 1.1) рассчитываем Σy, Σx, Σyx, Σx2, Σy2.
Таблица 1.1 Расчетная таблица
| y | x | yx |
x2 |
y2 |
|
|
Аi |
|
| 1 | 35,8 | 9,4 | 336,520 | 88,360 | 1281,640 | 41,559 | -5,759 | 16,087 |
| 2 | 22,5 | 2,5 | 56,250 | 6,250 | 506,250 | 22,248 | 0,252 | 1,122 |
| 3 | 28,3 | 3,9 | 110,370 | 15,210 | 800,890 | 26,166 | 2,134 | 7,541 |
| 4 | 26,0 | 4,3 | 111,800 | 18,490 | 676,000 | 27,285 | -1,285 | 4,944 |
| 5 | 18,4 | 2,1 | 38,640 | 4,410 | 338,560 | 21,128 | -2,728 | 14,827 |
| 6 | 31,8 | 6,0 | 190,800 | 36,000 | 1011,240 | 32,043 | -0,243 | 0,765 |
| 7 | 30,5 | 6,3 | 192,150 | 39,690 | 930,250 | 32,883 | -2,383 | 7,813 |
| 8 | 29,5 | 5,2 | 153,400 | 27,040 | 870,250 | 29,804 | -0,304 | 1,032 |
| 9 | 41,5 | 6,8 | 282,200 | 46,240 | 1722,250 | 34,282 | 7,218 | 17,392 |
| 10 | 41,3 | 8,2 | 338,660 | 67,240 | 1705,690 | 38,201 | 3,099 | 7,504 |
| Итого | 305,6 | 54,7 | 1810,790 | 348,930 | 9843,020 | 305,600 | 0 | 79,027 |
| Среднее значение | 30,56 | 5,47 | 181,079 | 34,893 | 984,302 | - | - | - |
|
|
7,098 | 2,23 | - | - | - | - | - | - |
|
|
50,381 | 4,973 | - | - | - | - | - | - |
Система нормальных уравнений составит
![]()
Используем следующие формулы для нахождения параметров:
![]() = 2,799
= 2,799
![]() 305,6 - 2,799*5,47 = 15,251
305,6 - 2,799*5,47 = 15,251
Уравнение парной линейной регрессии:
![]() = 15,251 + 2,799* x
= 15,251 + 2,799* x
Величина коэффициента регрессии b = 2,799 означает, что с ростом инвестиций в основной капитал на 1 тыс. руб. доля ВРП на душу населения растет в среднем на 2,80 %-ных пункта.
Знак при свободном члене уравнения положительный, следовательно связь прямая.
3. Рассчитаем линейный коэффициент корреляции:
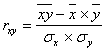 или
или ![]()
где ![]() ,
, ![]() - средние квадратические
отклонения признаков x и y, соответственно
- средние квадратические
отклонения признаков x и y, соответственно
Так как ![]() = 2,23,
= 2,23, ![]() = 7,098, то
= 7,098, то
![]() = 0,879, что означает тесную
прямую связь рассматриваемых признаков
= 0,879, что означает тесную
прямую связь рассматриваемых признаков
Коэффициент детерминации составит
![]() = 0,773
= 0,773
Вариация результата (y) на 77,3% объясняется вариацией фактора (x). На долю прочих факторов, не учитываемых в регрессии, приходится 22,7%.
4.
Средняя ошибка аппроксимации
(![]() )
находится как средняя арифметическая простая из индивидуальных ошибок
)
находится как средняя арифметическая простая из индивидуальных ошибок
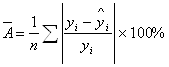 =
= ![]() =7,9%,
=7,9%,
(см. последнюю графу расчетной табл. 1.1.).
Ошибка аппроксимации
показывает хорошее соответствие расчетных (![]() ) и фактических (y) данных: среднее отклонение
составляет 7,9%.
) и фактических (y) данных: среднее отклонение
составляет 7,9%.
5. Стандартная ошибка регрессии рассчитывается по следующей формуле:
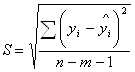 ,
,
где m – число параметров при переменных x.
В нашем примере стандартная ошибка регрессии
![]() = 3,782
= 3,782
6. Оценку статистической значимости построенное модели регрессии в целом производится с помощью F-критерия Фишера. Фактическое значение F-критерия для парного линейного уравнения регрессии определяется как
F = ![]()
где Сфакт = ![]() - факторная,
или объясненная регрессия, сумма квадратов; Сост =
- факторная,
или объясненная регрессия, сумма квадратов; Сост = ![]() - остаточная сумма
квадратов;
- остаточная сумма
квадратов;
![]() - коэффициент детерминации.
- коэффициент детерминации.
В нашем примере F-критерий Фишера будет равен (см. приложение №1):
F = ![]() = 27,233
= 27,233
Табличное значение F-критерия при числе степеней свободы 1 и 8 и уровне значимости 0,05 составит: 0,05 F1,8 = 5,32, т. е. фактическое значение F (Fфакт = 27,233) превышает табличное (Fтабл = 5,32), и можно сделать вывод, что уравнение регрессии статистически значимо. Следовательно гипотеза Н0 отклоняется.
Чтобы оценить значимость отдельных параметров уравнения, надо по каждому из параметров определить его стандартные ошибки: mb и ma.
Стандартная ошибка коэффициента регрессии определяется по формуле:
mb = 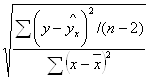 =
=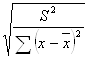
где S2 – остаточная дисперсия на одну степень свободы.
Стандартная ошибка параметра a определяется по формуле:
ma = 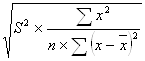 .
.
Для нахождения стандартных ошибок строим расчетную таблицу (см. приложение №1).
Для нашего примера величина стандартной ошибки коэффициента регрессии составила:
mb =![]() = 0,536.
= 0,536.
Величина стандартной ошибки параметра a составила:
ma = ![]() = 3,168
= 3,168
Для оценки существенности коэффициента регрессии и параметра a их величины сравниваются с их стандартными ошибками, т. е. определяются фактические значения t-критерия Стьюдента:
tb =![]() , ta =
, ta = ![]() .
.
Для нашего примера
tb =![]() = 5,222, ta =
= 5,222, ta = ![]() = 4,814
= 4,814
Фактические значения t-критерии превосходят табличные значения:
tb =5,222 > tтабл = 2,306; ta = 4,814 > tтабл = 2,306
Поэтому гипотеза Н0 отклоняется, т. е. a и b не случайно отличаются от нуля, а статистически значимы.
7. Полученные оценки
уравнения регрессии позволяют использовать его для прогноза. Для расчета
точечного прогноза ![]() подставим в уравнение регрессии
заданное значение факторного признака
подставим в уравнение регрессии
заданное значение факторного признака ![]() . Если прогнозное значение
инвестиций в основной капитал составит:
. Если прогнозное значение
инвестиций в основной капитал составит:
![]() = 9,4*0,8 = 7,52 тыс. руб
= 9,4*0,8 = 7,52 тыс. руб
Тогда прогнозное значение ВРП на душу населения составит:
![]() = 15,251 + 2,799* 7,52 = 36,299
тыс. руб.
= 15,251 + 2,799* 7,52 = 36,299
тыс. руб.
Доверительный интервал прогноза определяется с вероятностью (0,95) как
![]()
![]() ,
,
где tтабл – табличное значение t-критерия Стьюдента для уровня
значимости ![]() (1-0,95)
и числа степеней свободы (n-2)
для парной линейной регрессии;
(1-0,95)
и числа степеней свободы (n-2)
для парной линейной регрессии; ![]() - стандартная ошибка точечного
прогноза, которая рассчитывается по формуле:
- стандартная ошибка точечного
прогноза, которая рассчитывается по формуле:
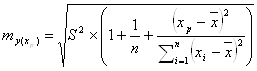
В нашем примере стандартная ошибка прогноза составила
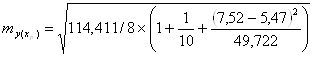 = 4,116
= 4,116
Предельная ошибка прогноза, которая в 95% случаев не будет превышена, составит:
![]() =
=![]() = 2,306 * 4,116 = 9,491.
= 2,306 * 4,116 = 9,491.
Доверительный интервал прогноза
γ![]() = 36,299
= 36,299 ![]() 9,491;
9,491;
γ![]() min = 36,299 – 9,491 = 26,808 тыс. руб.
min = 36,299 – 9,491 = 26,808 тыс. руб.
γ![]() mаx = 36,299 + 9,491 = 45,79 тыс. руб.
mаx = 36,299 + 9,491 = 45,79 тыс. руб.
Выполненный прогноз ВРП
на душу населения оказался надежным (р = 1 - ![]() = 0,95), но не точным, так как
диапазон верхней и нижней границ доверительного интервала Dγ составляет 1,708 раза:
= 0,95), но не точным, так как
диапазон верхней и нижней границ доверительного интервала Dγ составляет 1,708 раза:
Dγ = γ![]() mаx / γ
mаx / γ![]() min = 45,79 / 26,808 = 1,708.
min = 45,79 / 26,808 = 1,708.
Задача 2
Зависимость валовой продукции сельского хозяйства (y – млн. руб.) от валового производства молока (x1 – тыс. руб.) и мяса (x2 – тыс. руб.) на 100 га сельскохозяйственных угодий по 26 районам области характеризуется следующим образом:
![]() = - 2,229 + 0,039* x1 + 0,303* x2 R2 = 0,956.
= - 2,229 + 0,039* x1 + 0,303* x2 R2 = 0,956.
Матрица парных коэффициентов корреляции и средние значения:
| y |
x1 |
x2 |
Среднее | |
| y | 1 | 25,8 | ||
|
x1 |
0,717 | 1 | 364,9 | |
|
x2 |
0,930 | 0,489 | 1 | 45,3 |
Задание
1. Оцените значимость уравнения регрессии с помощью F-критерия Фишера с вероятностью 0,95. Сделайте выводы.
2. Найдите скорректированный коэффициент множественной корреляции.
3. Постройте уравнение множественной регрессии в стандартизованном масштабе и сделайте вывод.
4. Найдите частные средние коэффициенты эластичности и корреляции; сделайте выводы.
5. Постройте таблицу дисперсионного
анализа для оценки целесообразности включения в модель фактора x2 после фактора x1, если известно, что ![]() = 1350,5.
= 1350,5.
6. Оцените значимость интервала при факторе x2 через t-критерий Стьюдента и дайте интервальную оценку коэффициента регрессии с вероятностью 0,95.
7. Найдите стандартную ошибку регрессии.
Решение
1. Оценку значимости уравнения регрессии в целом дает F-критерия Фишера:
Fфакт = ![]()
где m- число факторных признаков в уравнении регрессии; R – линейный коэффициент множественной корреляции.
В нашем примере F-критерий Фишера составляет
Fфакт = ![]() = 249,864
= 249,864
Fтабл = 3,42; α = 0,05.
Сравнивая Fтабл и Fфакт, приходим к выводу о необходимости отклонить гипотезу Н0, так как Fтабл = 3,42 < Fфакт = 249,864. С вероятностью 0,95 делаем заключение о статистической значимости уравнения в целом и показателя тесноты связи R2.
2. Скорректированный коэффициент множественной корреляции находится как корень из скорректированного коэффициента множественной детерминации (R2 скорр):
R скор = ![]() =
=![]() =
= ![]() = 0,976
= 0,976
3. Линейное уравнение множественной регрессии y от x1 и x2 имеет вид:
4. y = a + b1*x1 + b2*x2.
5. По условию оно нам дано:
![]() = - 2,229 + 0,039* x1 + 0,303* x2
= - 2,229 + 0,039* x1 + 0,303* x2
Построим искомое уравнение в стандартизованном масштабе:
ty = β1*tx1 + β2*tx2.
Расчет β-коэффициентов выполним по формулам:
β1 = ![]() =
= ![]() = 0,345;
= 0,345;
β2 = ![]() =
= ![]() = 0,761.
= 0,761.
Получим уравнение
ty = 0,345*tx1 + 0,761*tx2.
6. Для характеристики относительной силы влияния x1 и x2 на y рассчитаем средние коэффициенты эластичности:
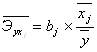 ;
;
![]() = 0,552%;
= 0,552%; ![]() = 0,532%.
= 0,532%.
С увеличением валового производства молока x1 на 1% от его среднего уровня валовая продукция сельского хозяйства y возрастает на 0,55% от своего среднего уровня; при повышении валового производства мяса x2 на 1% валовая продукция сельского хозяйства y возрастает на 0,53% от своего среднего уровня. Очевидно, что сила влияния валового производства молока x1 на валовую продукцию сельского хозяйства y оказалась большей, чем сила влияния валового производства мяса x2, но правда не намного.
Частные коэффициенты корреляции рассчитываются по формуле:
 =
= ![]() = 0,817,
= 0,817,
т.е. при закреплении фактора x2 на постоянном уровне корреляция y и x1 оказывается более высокой (0,817 против 0,717);
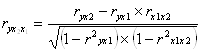 =
= ![]() = 0,953,
= 0,953,
т. е. при закреплении фактора x1 на постоянном уровне влияние фактора x2 на y оказывается более высокой (0,953 против 0,930);
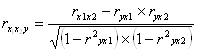 =
= ![]() = - 0,692
= - 0,692
7. Результаты дисперсионного анализа представлены в табл. 2.1.
Таблица 2.1
| Вариация результата, y | Число степеней свободы | Сумма квадратов отклонений, S |
Дисперсия на одну степень свободы, s2 |
Fфакт |
Fтабл α =0,05, k1 = 2, k2 = 23 |
| Общая | Df = n-1 = 25 | 35113 | - | - | - |
|
Факторная - за счет x1 - за счет дополнительного x2 |
k1 = m = 2 1 1 |
33568,028 18051,207 15516,821 |
16784,014 18051,207 15516,821 |
249,864 268,728 230,999 |
3,42 4,28 4,28 |
| Остаточная |
k2 = n-m-1 = 23 |
1544,972 | 67,173 | - | - |
Sобщ = ![]() = 1350,5 * 26 = 35113;
= 1350,5 * 26 = 35113;
Sфакт = ![]() = 1350,5 * 26 * 0,956 = 33568,028;
= 1350,5 * 26 * 0,956 = 33568,028;
Sфакт x1 =![]() = 1350,5 * 26 * 0,7172
= 18051,207;
= 1350,5 * 26 * 0,7172
= 18051,207;
Sфакт x2 = Sфакт - Sфакт x1 = 33568,028 – 18051,207 = 15516,821;
Sост = ![]() = Sобщ - Sфакт = 35113 – 33568,028 = 1544,972;
= Sобщ - Sфакт = 35113 – 33568,028 = 1544,972;
Fфакт = ![]() =
= ![]() = 249,864;
= 249,864;
Fфактx1 = ![]() =
= ![]() = 268,728;
= 268,728;
Fчастнx2 = ![]() =
= ![]() = 230,999.
= 230,999.
![]() = 16784,014;
= 16784,014;
![]() = 15516,821;
= 15516,821;
![]() = 18051,207
= 18051,207
Включение в модель фактора x2 после фактора x1 оказалось статистически значимым и оправданным: прирост факторной дисперсии (в расчете на одну степень свободы) оказался существенным, т. е. следствием дополнительного включения в модель систематически действующего фактора x2, так как Fчастнx2 = 230,999 > Fтабл = 4,28.
8. Оценка с помощью t-критерия Стьюдента значимости коэффициента b2 связана с сопоставлением его значения с величиной его случайной ошибки: mb2.
Расчет значения t-критерия Стьюдента для коэффициента регрессии линейного уравнения находится по следующей формуле:
![]() = 15,199.
= 15,199.
При α = 0,05; df = n-m-1 = 26-2-1 = 23;
tтабл = 2,07. Сравнивая tтабл и tфакт, приходим к выводу, что так как ![]() = 15,199 > 2,07 = tтабл, коэффициент регрессии b2 является статистически значимым, надежным, на него
можно опираться в анализе и в прогнозе.
= 15,199 > 2,07 = tтабл, коэффициент регрессии b2 является статистически значимым, надежным, на него
можно опираться в анализе и в прогнозе.
9. Стандартная ошибка регрессии рассчитывается по следующей формуле:
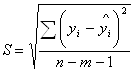 =
= ![]() = 8,196.
= 8,196.
Задача 3
Рассматривается модель вида

где
Сt – расходы на потребление в текущий период,
Сt-1 – расходы на потребление в предыдущий период,
Rt – доход текущего периода,
Rt-1 – доход предыдущего периода,
Yt – инвестиции текущего периода.
Ей соответствует следующая приведенная форма (построена по районам области)
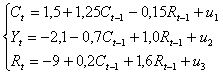
Задание
1. Проведите идентификацию модели.
2. Укажите способы оценки параметров каждого уравнения структурной модели.
3. Найдите структурные коэффициенты каждого уравнения, если известны следующие данные:
| № | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|
Yt |
4 | 4 | 6 | 10 | 9 | 8 | 7 | 6 | 8 | 12 | 8 | 16 |
|
Сt |
14 | 13 | 15 | 20 | 20 | 14 | 16 | 12 | 12 | 21 | 12 | 17 |
|
Rt-1 |
15 | 14 | 16 | 22 | 26 | 18 | 18 | 15 | 19 | 28 | 18 | 26 |
|
Сt-1 |
12 | 11 | 12 | 15 | 17 | 12 | 14 | 10 | 11 | 20 | 12 | 16 |
Решение
1. Модель имеет три эндогенные Н (Сt, Yt, Rt). Причем переменная Rt задана тождеством. Поэтому практически статистическое решение необходимо только для первых двух уравнений системы, которые необходимо проверить на идентификацию. Модель содержит две предопределенные D (Сt-1, Rt-1) переменные.
Проверим каждое уравнение системы на необходимое и достаточное условия идентификации.
Проверим необходимое условие идентификации для уравнений модели.
I уравнение.
Н: эндогенных переменных – 2 (Сt, Rt), отсутствующих предопределенных переменных – 1 (Rt-1).
Следовательно, по счетному правилу D + 1 = H (1 + 1 = 2) уравнение идентифицируемо.
II уравнение.
Н: эндогенных переменных – 1 (Yt); переменная Rt в данном уравнении не рассматривается как эндогенная, так как она участвует в уравнении не самостоятельно, а вместе с переменной Rt-1.
отсутствующих предопределенных переменных – 1 (Сt-1).
Следовательно, по счетному правилу D + 1 > H (1 + 1 > 1) уравнение сверхидентифицировано.
III уравнение.
Третье уравнение представляет собой тождество, параметры которого известны. Необходимости в его идентификации нет.
Следовательно, рассматриваемая в целом структурная модель сверхидентифицируема по счетному правилу.
Проверим для каждого из уравнений достаточное условие идентификации.
Для этого составим матрицу коэффициентов при переменных модели:
|
Сt |
Yt |
Rt |
Rt-1 |
Сt-1 |
|
| I уравнение | -1 | 0 |
b11 |
0 |
b12 |
| II уравнение | 0 | -1 |
b21 |
-b21 |
0 |
| III уравнение | 1 | 1 | -1 | 0 | 0 |
В соответствии с достаточным условием идентификации определитель матрицы коэффициентов при переменных, не входящих в исследуемое уравнение, не должен быть равен нулю, а ранг матрицы должен быть равен числу эндогенных переменных модели минус 1, т. е. 3-1=2.
I уравнение.
Матрица коэффициентов при переменных, не входящих в уравнение, имеет вид:
| Уравнение | Отсутствующие переменные | |
|
Yt |
Rt-1 |
|
| Второе | -1 |
-b21 |
| Третье | 1 | 0 |
Определитель матрицы не
равен 0 (Det A = -1*0 – (1*-b21) ![]() 0), ранг матрицы равен 2;
следовательно, выполняется достаточное условие идентификации.
0), ранг матрицы равен 2;
следовательно, выполняется достаточное условие идентификации.
II уравнение.
Матрица коэффициентов при переменных, не входящих в уравнение, имеет вид:
| Уравнение | Отсутствующие переменные | |
|
Сt |
Сt-1 |
|
| Первое | -1 |
b12 |
| Третье | 1 | 0 |
Определитель матрицы не
равен 0 (Det A = -1*0 – (1*b12) ![]() 0.), ранг матрицы равен 2;
следовательно, выполняется достаточное условие идентификации.
0.), ранг матрицы равен 2;
следовательно, выполняется достаточное условие идентификации.
2. Первое уравнение идентифицируемое, следовательно, для его решения применяется косвенный метод наименьших квадратов.
Косвенный метод наименьших квадратов (МНК):
- Составить приведенную форму модели и определить численные значения параметров каждого уравнения системы обычным МНК.
- Путем алгебраических преобразований переходим от приведенной формы к уравнениям структурной формы модели и получаем численные оценки структурных параметров.
Для решения второго уравнения, а оно у нас сверхидентифицируемое, применяется – двухшаговый метод наименьших квадратов.
Двушшаговый метод:
- Составить приведенную форму модели и определить численные значения параметров каждого уравнения системы обычным МНК.
- Выявляем эндогенные переменные, находящиеся в правой части структурного уравнения, параметры которого определяют двухшаговым МНК, и находим расчетные значения по соответствующим уравнениям приведенной формы модели.
- Обычным МНК определяем параметры структурного уравнения, используя в качестве исходных данных фактические значения предопределенных переменных и расчетные значения эндогенных переменных, стоящих в правой части данного структурного уравнения.
3. Найдем структурные коэффициенты первого и второго уравнений на основании исходных данных.
Составим расчетную таблицу (Rt = Ct + Yt ; обозначим d Rt = Rt - Rt-1).
Таблица 3.1 Расчетная таблица
| № |
Yt |
Ct |
Rt-1 |
Ct-1 |
Rt |
dRt |
Yt*dRt |
(dRt)2 |
(Rt)2 |
(Ct-1*Rt |
Ct*Rt |
(Ct-1)2 |
Ct*Ct-1 |
| 1 | 4 | 14 | 15 | 12 | 18 | 3 | 12 | 9 | 324 | 216 | 252 | 144 | 168 |
| 2 | 4 | 13 | 14 | 11 | 17 | 3 | 12 | 9 | 289 | 187 | 221 | 121 | 143 |
| 3 | 6 | 15 | 16 | 12 | 21 | 5 | 30 | 25 | 441 | 252 | 315 | 144 | 180 |
| 4 | 10 | 20 | 22 | 15 | 30 | 8 | 80 | 64 | 900 | 450 | 600 | 225 | 300 |
| 5 | 9 | 20 | 26 | 17 | 29 | 3 | 27 | 9 | 841 | 493 | 580 | 289 | 340 |
| 6 | 8 | 14 | 18 | 12 | 22 | 4 | 32 | 16 | 484 | 264 | 308 | 144 | 168 |
| 7 | 7 | 16 | 18 | 14 | 23 | 5 | 35 | 25 | 529 | 322 | 368 | 196 | 224 |
| 8 | 6 | 12 | 15 | 10 | 18 | 3 | 18 | 9 | 324 | 180 | 216 | 100 | 120 |
| 9 | 8 | 12 | 19 | 11 | 20 | 1 | 8 | 1 | 400 | 220 | 240 | 121 | 132 |
| 10 | 12 | 21 | 28 | 20 | 33 | 5 | 60 | 25 | 1089 | 660 | 693 | 400 | 420 |
| 11 | 8 | 12 | 18 | 12 | 20 | 2 | 16 | 4 | 400 | 240 | 240 | 144 | 144 |
| 12 | 16 | 17 | 26 | 16 | 33 | 7 | 112 | 49 | 1089 | 528 | 561 | 256 | 272 |
| ∑ | 98 | 186 | 235 | 162 | 284 | 49 | 442 | 245 | 7110 | 4012 | 4594 | 2284 | 2611 |
Коэффициенты уравнений найдем методом наименьший квадратов:

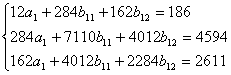
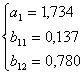 (решение системы найдено в
программе MATLAB)
(решение системы найдено в
программе MATLAB)
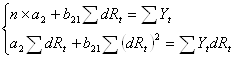

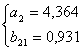
Таким образом, получена система структурных уравнений
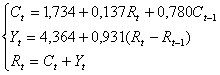
Задача 4
Динамика номинальной среднемесячной заработной платы одного работника области характеризуется следующими данными:
| Месяц | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| Тыс. руб. | 3,2 | 3,1 | 3,5 | 3,5 | 3,7 | 4,0 | 4,1 | 4,0 | 4,1 | 4,2 | 4,3 | 5,4 |
Задание
1. Определите коэффициент автокорреляции первого порядка и дайте его интерпретацию.
2. Постройте линейное уравнение тренда. Дайте интерпретацию параметрам.
3. С помощью критерия Дарбина – Уотсона сделайте выводы относительно автокорреляции в остатках в рассматриваемом уравнении.
4. Дайте интервальный прогноз ожидаемого уровня номинальной заработной платы на январь следующего года.
Решение
1. Коэффициент автокорреляции первого порядка рассчитывается по следующей формуле:
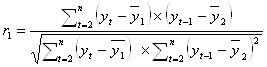
где 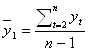 ;
; 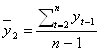
Для расчета коэффициента автокорреляции первого порядка составим расчетную таблицу:
Таблица 4.1 Расчетная таблица
| t |
yt |
yt-1 |
|
|
|
|
|
| 1 | 3,2 | - | - | - | - | - | - |
| 2 | 3,1 | 3,2 | -0,9 | 2,8 | -2,5 | 7,9 | 0,8 |
| 3 | 3,5 | 3,1 | -0,5 | 2,7 | -1,3 | 7,3 | 0,2 |
| 4 | 3,5 | 3,5 | -0,5 | 3,1 | -1,5 | 9,7 | 0,2 |
| 5 | 3,7 | 3,5 | -0,3 | 3,1 | -0,9 | 9,7 | 0,1 |
| 6 | 4,0 | 3,7 | 0,0 | 3,3 | 0,0 | 11,0 | 0,0 |
| 7 | 4,1 | 4,0 | 0,1 | 3,6 | 0,4 | 13,0 | 0,0 |
| 8 | 4,0 | 4,1 | 0,0 | 3,7 | 0,0 | 13,8 | 0,0 |
| 9 | 4,1 | 4,0 | 0,1 | 3,6 | 0,4 | 13,0 | 0,0 |
| 10 | 4,2 | 4,1 | 0,2 | 3,7 | 0,8 | 13,8 | 0,0 |
| 11 | 4,3 | 4,2 | 0,3 | 3,8 | 1,2 | 14,5 | 0,1 |
| 12 | 5,4 | 4,3 | 1,4 | 3,9 | 5,5 | 15,3 | 2,0 |
| Итого | 47,1 | 41,7 | 0,0 | 37,3 | 2,1 | 129 | 3,4 |
![]() = 3,991;
= 3,991;
![]() = 0,391.
= 0,391.
Коэффициент автокорреляции первого порядка равен:
![]() =
= ![]() = 0,1.
= 0,1.
Это значение (0,1) свидетельствует о слабой зависимости текущих уровней ряда от непосредственно им предшествующих уровней, т. е. слабой зависимости между номинальной среднемесячной заработной платы текущего и непосредственно предшествующего месяца.
2. Линейное уравнение трендов имеет вид:
![]()
Параметры a и b этой модели определяются обычным МНК. Система нормальных уравнений следующая:
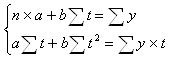
По исходным данным составит расчетную таблицу:
Таблица 4.2 Расчетная таблица
| t | y | yt |
t2 |
|
| 1 | 3,2 | 3,2 | 1 | |
| 2 | 3,1 | 6,2 | 4 | |
| 3 | 3,5 | 10,5 | 9 | |
| 4 | 3,5 | 14 | 16 | |
| 5 | 3,7 | 18,5 | 25 | |
| 6 | 4 | 24 | 36 | |
| 7 | 4,1 | 28,7 | 49 | |
| 8 | 4 | 32 | 64 | |
| 9 | 4,1 | 36,9 | 81 | |
| 10 | 4,2 | 42 | 100 | |
| 11 | 4,3 | 47,3 | 121 | |
| 12 | 5,4 | 64,8 | 144 | |
| Итого | 78 | 47,1 | 328,1 | 650 |
| Средние | 6,5 | 3,925 | 27,342 | 54,167 |
Система нормальных уравнений составит:
![]()
Используем следующие формулы для нахождения параметров:
![]() = 0,153;
= 0,153;
![]() = 2,927.
= 2,927.
Линейное уравнение трендов
Параметр b = 0,153 означает, что с увеличение месяца на 1 месяц номинальная среднемесячная заработная плата увеличивается в среднем на 0,153 тыс. руб.
3. Для оценки существенности автокорреляции остатков используют критерий Дарбина – Уотсона:
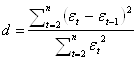
Коэффициент автокорреляции остатков первого порядка может определятся как:

Для каждого момента
(периода) времени t = 1 : n значение компонента ![]() определяется как
определяется как
![]()
Составим расчетную таблицу
Таблица 4.3 Расчетная таблица
| t | y |
|
|
|
|
|
|
|
|
|
| 1 | 3,2 | 3,080 | 0,120 | - | - | - | 0,014 | - | - | |
| 2 | 3,1 | 3,233 | -0,133 | 0,120 | -0,253 | 0,064 | 0,018 | 0,018 | -0,016 | |
| 3 | 3,5 | 3,386 | 0,114 | -0,133 | 0,247 | 0,061 | 0,013 | 0,013 | -0,015 | |
| 4 | 3,5 | 3,539 | -0,039 | 0,114 | -0,153 | 0,023 | 0,002 | 0,002 | -0,004 | |
| 5 | 3,7 | 3,692 | 0,008 | -0,039 | 0,047 | 0,002 | 0,000 | 0,000 | 0,000 | |
| 6 | 4 | 3,845 | 0,155 | 0,008 | 0,147 | 0,022 | 0,024 | 0,024 | 0,001 | |
| 7 | 4,1 | 3,998 | 0,102 | 0,155 | -0,053 | 0,003 | 0,010 | 0,010 | 0,016 | |
| 8 | 4 | 4,151 | -0,151 | 0,102 | -0,253 | 0,064 | 0,023 | 0,023 | -0,015 | |
| 9 | 4,1 | 4,304 | -0,204 | -0,151 | -0,053 | 0,003 | 0,042 | 0,042 | 0,031 | |
| 10 | 4,2 | 4,457 | -0,257 | -0,204 | -0,053 | 0,003 | 0,066 | 0,066 | 0,052 | |
| 11 | 4,3 | 4,610 | -0,310 | -0,257 | -0,053 | 0,003 | 0,096 | 0,096 | 0,080 | |
| 12 | 5,4 | 4,763 | 0,637 | -0,310 | 0,947 | 0,897 | 0,406 | 0,406 | -0,197 | |
| Σ | 1,145 | 0,714 | 0,7 | -0,067 |
Критерий Дарбина –
Уотсона равен ![]()
![]() = 1,604.
= 1,604.
Коэффициент
автокорреляции равен ![]() = - 0,096.
= - 0,096.
Фактическое значение d сравниваем с табличными значениями при 5%-ном уровне значимости. При n = 12 месяцев и m = 1 (число факторов) нижнее значение d’ равно 0,97, а верхнее – 1,33. Фактическое значение d=1,604 > d’=1,33, следовательно, автокорреляция остатков отсутствует.
Чтобы проверить значимость отрицательного коэффициента автокорреляции, сравним фактическое значение d с (4-dL ) и (4-dU):
|
4-dL |
4-dU |
|
| 1,604 | 3,03 | 2,67 |
Из таблицы видно, что в обоих случаях фактическое значение меньше сравниваемых. Это означает отсутствие в остатках автокорреляции.
Так же принято считать, что если фактическое значение d близко к 2, то автокорреляции остатков нет. В нашем примере это совпадает.
4. В соответствии с интерпретацией параметров линейного тренда, каждый последующий уровень ряда есть сумма предыдущего уровня и среднего цепного абсолютного прироста. Тогда:
а) Точечный прогноз составит:
Точечный прогноз по
уравнению тренда – это расчетное значение переменной ![]() , полученное путем подстановки в уравнение тренда
значений
, полученное путем подстановки в уравнение тренда
значений
![]()
(n – длина динамического ряда, l – период упреждения).
![]() = 2,927 + 0,153* (12 + 1) = 4,916
(тыс. руб.)
= 2,927 + 0,153* (12 + 1) = 4,916
(тыс. руб.)
ожидаемый уровень номинальной заработной платы на январь следующего года.
б) Интервальный прогноз составит:
Доверительный интервал прогноза определяется с вероятностью 0,95, как:
![]()
![]() ;
;
где, tтабл=2,2281 - табличное значение t-критерия
Стьюдента для уровня значимости α=0,05 и числа степеней свободы (n – 2 = 12 – 2 = 10); ![]() - стандартная ошибка
точечного прогноза, которая рассчитывается по формуле:
- стандартная ошибка
точечного прогноза, которая рассчитывается по формуле:
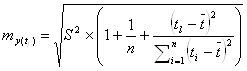
Данные необходимые для расчета представим в таблице.
Таблица 4.4 Расчетная таблица
![]() = 0,714 - остаточная сумма
квадратов.
= 0,714 - остаточная сумма
квадратов.
![]() = 0,267 – среднее квадратическое
отклонение остаточной суммы квадратов
= 0,267 – среднее квадратическое
отклонение остаточной суммы квадратов
![]()
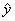 = 0,313
= 0,313
Таким образом, прогнозируемый уровень номинальной заработной платы на январь следующего года составит
![]()
![]() = 4,916 ± 2,2281*0,313 = 4,916 ± 0,697 тыс. руб.
= 4,916 ± 2,2281*0,313 = 4,916 ± 0,697 тыс. руб.
Выполненный прогноз уровня
номинальной заработной платы на январь следующего года оказался надежным (р = 1
- ![]() = 0,95),
и не точным, так как диапазон верхней и нижней границ доверительного интервала Dγ составляет 1,33 раза
= 0,95),
и не точным, так как диапазон верхней и нижней границ доверительного интервала Dγ составляет 1,33 раза
Dγ = γ![]() mаx / γ
mаx / γ![]() min = 5,613 / 4,219 = 1,33.
min = 5,613 / 4,219 = 1,33.
Динамика численности незанятых граждан и объема платных услуг населению в регионе характеризуется следующими данными
| Месяц |
Число незанятых граждан тыс.чел .,x1 |
Объем платных услуг населению млрд.руб., y1 |
| Январь | 44,0 | 6,5 |
| Февраль | 45,5 | 7,0 |
| Март | 47,9 | 7,0 |
| Апрель | 48,3 | 7,4 |
| Май | 49,1 | 7,5 |
| Июнь | 49,9 | 7,2 |
| Июль | 50,5 | 7,5 |
| Август | 51,9 | 7,9 |
| Сентябрь | 52,3 | 8,2 |
| Октябрь | 52,3 | 8,5 |
| Ноябрь | 53,5 | 8,9 |
| Декабрь | 54,7 | 9,2 |
В результате аналитического выравнивания получены следующие уравнения трендов и коэффициент детерминации(t=1÷12):
А) для объема платных услуг населению
Ŷ1=6,3061+0,2196t ,R2=0,9259
Б) для численности незанятых граждан
̂х1=43,724+0,8937t , R2=0,989
Задание
1. Дайте интерпретацию параметров уровней трендов.
2. Определите коэффициент корреляции между временными рядами, используя:
А) непосредственно исходные уровни
Б)о тклонения от основной тенденции
3). Сделайте вывод о тесноте связи между временными рядами.
4). Постройте вывод о тесноте связи между временными рядами. Дайте интерпретацию параметров уравнения.
Решение
Наиболее простую экономическую интерпретацию имеют параметры линейного тренда. Параметры линейного тренда можно интерпретировать так:
а – начальный уровень временного ряда в момент времени t = 0;
b – средний за период абсолютный прирост уровней ряда.
Для исходной задачи начальный уровень ряда для выпуска товаров соответствует значению 6,3061 млрд. руб., средний за период абсолютный прирост уровней ряда составляет 0,2196 млрд. руб. Параметр b > 0, значит уровни ряда равномерно возрастают на 0,2196 млрд. руб. каждый год.
Для числа незанятых граждан тыс,чел коэффициент а - начальный уровень ряда соответствует значению 43,724 тыс. чел.; абсолютное ускорение увеличения среднесписочной численности работников соответствует 0,8937.
Рассчитаем коэффициент корреляции между временными рядами, используя непосредственно исходные уровни. Коэффициент корреляции характеризует тесноту линейной связи между изучаемыми признаками. Определяем его по формуле
rxy=![]()
Расчет параметров коэффициента корреляции
| № | X | Y | X² | x·y | y² | ŷ |
|
|||||
|
|
||||||||||||
| 1. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||
| 1. | 44 | 6,5 | 1936 | 286 | 42,25 | 15,96 | 78,9 | |||||
| 2. | 45,5 | 7 | 2070,25 | 318,5 | 49 | 16,2979 | 80,1 | |||||
| 3. | 46,8 | 7 | 2190,24 | 327,6 | 49 | 16,82494 | 82,08 | |||||
| 4. | 47,9 | 7,4 | 2294,41 | 354,46 | 54,76 | 17,08846 | 82,34 | |||||
| 5. | 48,8 | 7,5 | 2381,44 | 48,8 | 56,25 | 17,2644 | 82,98 | |||||
| 6. | 49,1 | 7,2 | 2410,81 | 353,52 | 51,84 | 17,25 | 83,62 | |||||
| 7. | 49,9 | 7,5 | 2490,01 | 374,25 | 56,25 | 17,3959 | 84,1 | |||||
| 8. | 50,5 | 7,9 | 2550,25 | 50,5 | 62,41 | 17,70334 | 85,22 | |||||
| 9. | 51,9 | 8,2 | 2693,61 | 425,58 | 67,24 | 17,79118 | 85,54 | |||||
| 10 | 52,3 | 8,5 | 2735,29 | 444,55 | 72,25 | 17,79118 | 85,85 | |||||
| 11 | 53,5 | 8,9 | 2862,25 | 476,15 | 79,21 | 18,0547 | 86,3 | |||||
| 12 | 54,7 | 9,2 | 2992,09 | 503,24 | 84,64 | 18,31822 | 87,46 | |||||
| ∑ | 594,9 | 92,8 | 29606,65 | 3963,15 | 725,1 | 207,7402 | 1011,49 | |||||
| ср.знач | 49,575 | 7,733333 | 2467,221 | 330,2625 | 60,425 | 17,31169 | 83,7075 |
sх = ![]() =
= ![]() = 3,08;
= 3,08;
sу = ![]() =
= ![]() =0,821.
=0,821.
rxy = ![]() = -20,7110 - связь слабая,
прямая.
= -20,7110 - связь слабая,
прямая.
При измерении корреляции между двумя временными рядами следует учитывать возможное существование ложной корреляции, что связано с наличием во временных рядах тенденции, т.е. зависимости обоих рядов от общего фактора времени. Для того чтобы устранить ложную корреляцию, следует коррелировать не сами уровни временных рядов, а их последовательные (первые или вторые) разности или отклонения от трендов (если последние не содержат тенденции).
Таким образом между временными рядами существует прямая слабая взаимосвязь.
Линейная регрессия сводится к нахождению уравнения вида
![]() = a + b*x
= a + b*x
Классический подход к оцениванию параметров линейной регрессии основан на методе наименьших квадратов.
Для линейных и нелинейных уравнений, приводимых к линейным, решается следующая система относительно a и b.
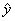 ,
,
Можно воспользоваться готовыми формулами, которые вытекают из этой системы
а = ![]() ;
;
b = ![]() =
=![]() = 0,008;
= 0,008;
а = 0,00286 – 0,701*0 = 7,334
Уравнение регрессии по отклонениям от трендов:
![]() = 7,334+ 0,008*х
= 7,334+ 0,008*х
Список используемой литературы
1. Практикум по эконометрике: Учеб. пособие / И. И. Елисеева, С. В. Курышева, Н. М. Гордеенко и др.; Под ред. И. И. Елисеевой. – М.: Финансы и статистика, 2001. – 192 с.
2. Эконометрика: Учебник / Под ред. И. И. Елисеевой. – М.: Финансы и статистика, 2001. – 344 с.
3. Мхитарян В.С., Архипова М.Ю. Эконометрика Московский международный институт эконометрики, информатики, финансов и права. - М., 2004. - 69 с.
4. Эконометрия - УП – Суслов – Ибрагимов – Талышева - Цыплаков - 2005 – 744 с.
Таблица 1.2 Расчетная таблица
| y | x |
|
( |
|
|
( |
|
( |
|
( |
|
| 1 | 35,8 | 9,4 | 5,240 | 27,458 | 41,559 | 10,999 | 120,978 | -5,759 | 33,166 | 3,930 | 15,445 |
| 2 | 22,5 | 2,5 | -8,060 | 64,964 | 22,248 | -8,312 | 69,089 | 0,252 | 0,064 | -2,970 | 8,821 |
| 3 | 28,3 | 3,9 | -2,260 | 5,108 | 26,166 | -4,394 | 19,307 | 2,134 | 4,554 | -1,570 | 2,465 |
| 4 | 26,0 | 4,3 | -4,560 | 20,794 | 27,285 | -3,275 | 10,726 | -1,285 | 1,651 | -1,170 | 1,369 |
| 5 | 18,4 | 2,1 | -12,160 | 147,866 | 21,128 | -9,432 | 88,963 | -2,728 | 7,442 | -3,370 | 11,357 |
| 6 | 31,8 | 6,0 | 1,240 | 1,538 | 32,043 | 1,483 | 2,199 | -0,243 | 0,059 | 0,530 | 0,281 |
| 7 | 30,5 | 6,3 | -0,060 | 0,004 | 32,883 | 2,323 | 5,396 | -2,383 | 5,679 | 0,830 | 0,689 |
| 8 | 29,5 | 5,2 | -1,060 | 1,124 | 29,804 | -0,756 | 0,572 | -0,304 | 0,092 | -0,270 | 0,073 |
| 9 | 41,5 | 6,8 | 10,940 | 119,684 | 34,282 | 3,722 | 13,853 | 7,218 | 52,100 | 1,330 | 1,769 |
| 10 | 41,3 | 8,2 | 10,740 | 115,348 | 38,201 | 7,641 | 58,385 | 3,099 | 9,604 | 2,730 | 7,453 |
| Σ | 305,6 | 54,7 | 0,000 | 503,884 | 305,600 | -0,001 | 389,468 | 0 | 114,411 | 0 | 49,722 |
| Сред. знач. | 30,56 | 5,47 | - | - | - | - | - | - | - | - | - |
Приложение 2.
Таблица значений F-критерия Фишера (двусторонний)
|
d.f.2= n - k - 1) степени свободы остаточной дисперсии |
степени свободы факторной дисперсии – d.f.1 = k |
|||||||||||
| k=1 | k=2 | k=3 | k=4 | |||||||||
Уровень значимости, α |
||||||||||||
| 0,10 | 0,05 | 0,01 | 0,10 | 0,05 | 0,01 | 0,10 | 0,05 | 0,01 | 0,10 | 0,05 | 0,01 | |
| 1 | 39,9 | 161,5 | 4052 | 49,5 | 199,5 | 5000 | 53,6 | 215,72 | 5403 | 55,8 | 224,57 | 5625 |
| 2 | 8,5 | 18,5 | 98,5 | 9,0 | 19,0 | 99,00 | 9,2 | 19,16 | 99,2 | 19,2 | 19,25 | 99,30 |
| 3 | 5,54 | 10,13 | 34,1 | 5,46 | 9,6 | 30,82 | 5,39 | 9,28 | 29,5 | 5,34 | 9,12 | 28,71 |
| 4 | 4,54 | 7,71 | 21,2 | 4,32 | 6,9 | 18,00 | 4,19 | 6,59 | 16,7 | 4,11 | 6,39 | 15,98 |
| 5 | 4,06 | 6,61 | 16,3 | 3,78 | 5,79 | 13,27 | 3,62 | 5,41 | 12,1 | 3,52 | 5,19 | 11,39 |
| 6 | 3,78 | 5,99 | 13,8 | 3,46 | 5,14 | 10,92 | 3,29 | 4,76 | 9,8 | 3,18 | 4,53 | 9,15 |
| 7 | 3,59 | 5,59 | 12,3 | 3,26 | 4,74 | 9,55 | 3,07 | 4,35 | 8,5 | 2,96 | 4,12 | 7,85 |
| 8 | 3,46 | 5,32 | 11,3 | 3,11 | 4,46 | 8,65 | 2,92 | 4,07 | 7,6 | 2,81 | 3,84 | 7,01 |
| 9 | 3,36 | 5,12 | 10,6 | 3,01 | 4,26 | 8,02 | 2,81 | 3,86 | 7,0 | 2,69 | 3,63 | 6,42 |
| 10 | 3,29 | 4,96 | 10,0 | 2,92 | 4,10 | 7,56 | 2,73 | 3,71 | 6,6 | 2,61 | 3,48 | 5,99 |
| 11 | 3,23 | 4,84 | 9,7 | 2,86 | 3,98 | 7,20 | 2,66 | 3,59 | 6,2 | 2,54 | 3,36 | 5,67 |
| 12 | 3,18 | 4,75 | 9,3 | 2,81 | 3,88 | 6,93 | 2,61 | 3,49 | 6,0 | 2,48 | 3,26 | 5,41 |
| 13 | 3,14 | 4,67 | 9,1 | 2,76 | 3,80 | 6,70 | 2,56 | 3,41 | 5,7 | 2,43 | 3,18 | 5,20 |
| 14 | 3,10 | 4,60 | 8,9 | 2,73 | 3,74 | 6,51 | 2,52 | 3,34 | 5,6 | 2,39 | 3,11 | 5,03 |
| 15 | 3,07 | 4,54 | 8,7 | 2,70 | 3,68 | 6,36 | 2,49 | 3,29 | 5,4 | 2,36 | 3,06 | 4,89 |
| 16 | 3,05 | 4,49 | 8,5 | 2,67 | 3,63 | 6,23 | 2,46 | 3,24 | 5,3 | 2,33 | 3,01 | 4,77 |
| 17 | 3,03 | 4,45 | 8,4 | 2,64 | 3,59 | 6,11 | 2,44 | 3,20 | 5,2 | 2,31 | 2,96 | 4,67 |
| 18 | 3,01 | 4,41 | 8,3 | 2,62 | 3,55 | 6,01 | 2,42 | 3,16 | 5,1 | 2,29 | 2,93 | 4,58 |
| 19 | 2,99 | 4,38 | 8,2 | 2,61 | 3,52 | 5,93 | 2,40 | 3,13 | 5,0 | 2,27 | 2,90 | 4,50 |
| 20 | 2,97 | 4,35 | 7,9 | 2,59 | 3,49 | 5,72 | 2,38 | 3,10 | 4,9 | 2,25 | 2,87 | 4,31 |
| 21 | … | 4,32 | 8,0 | … | 3,47 | 5,78 | … | 3,07 | 4,9 | … | 2,84 | 4,37 |
| 22 | 2,95 | 4,30 | 7,9 | 2,56 | 3,44 | 5,72 | 2,35 | 3,05 | 4,8 | 2,22 | 2,82 | 4,31 |
| 23 | … | 4,28 | 7,9 | … | 3,42 | 5,66 | … | 3,03 | 4,8 | … | 2,80 | 4,26 |
| 24 | 2,93 | 4,26 | 7,8 | 2,54 | 3,40 | 5,61 | 2,33 | 3,01 | 4,7 | 2,19 | 2,78 | 4,22 |
| 25 | … | 4,24 | 7,8 | … | 3,38 | 5,57 | … | 2,99 | 4,7 | … | 2,76 | 4,18 |
| 26 | 2,91 | 4,22 | 7,7 | 25,2 | 3,37 | 5,53 | 2,31 | 2,98 | 4,6 | 2,17 | 2,73 | 4,14 |
| 30 | 2,88 | 4,17 | 7,56 | 2,49 | 3,32 | 5,39 | 2,28 | 2,92 | 4,5 | 2,14 | 2,69 | 4,02 |
| 40 | 2,84 | 4,08 | 7,31 | 2,44 | 3,23 | 5,18 | 2,23 | 2,84 | 4,3 | 2,09 | 2,61 | 3,83 |
| 60 | 2,79 | 4,00 | 7,08 | 2,39 | 3,15 | 4,98 | 2,18 | 2,76 | 4,1 | 2,04 | 2,53 | 3,65 |
| 80 | 2,77 | 8,96 | 6,96 | 2,37 | 3,11 | 4,88 | 2,16 | 2,72 | 4,0 | 2,02 | 2,48 | 3,56 |
| 100 | 2,76 | 3,94 | 6,90 | 2,36 | 3,09 | 4,82 | 2,14 | 2,70 | 3,98 | 2,00 | 2,46 | 3,51 |
| ∞ | 2,71 | 3,84 | 6,63 | 2,30 | 3,00 | 4,61 | 2,08 | 2,60 | 3,78 | 1,94 | 2,37 | 3,32 |
Шкала атрибутивных оценок тесноты корреляционной зависимости
|
Значения показателей корреляции ( |
Атрибутивная оценка тесноты выявленной зависимости |
Значения показателей детерминации,
% ( |
| До 0,3 | Слабая | До 10 |
| 0,3 – 0,5 | Умеренная | 10 – 25 |
| 0,5 – 0,7 | Заметная | 25 – 50 |
| 0,7 – 0,9 | Тесная | 50 – 80 |
| 0,9 и более | Весьма тесная | 80 и более |
Приложение 4
Случайная ошибка коэффициента асимметрии для выборок разного объема
|
Объём выборки, |
|
|
| 4 | 1,014 | 0,926 |
| 5 | 0,913 | 0,866 |
| 6 | 0,845 | 0,816 |
| 7 | 0,794 | 0,775 |
| 8 | 0,752 | 0,739 |
| 9 | 0,717 | 0,707 |
| 10 | 0,687 | 0,679 |
| 11 | 0,661 | 0,655 |
| 12 | 0,637 | 0,632 |
| 13 | 0,616 | 0,612 |
| 14 | 0,597 | 0,594 |
| 15 | 0,580 | 0,577 |
| 16 | 0,564 | 0,562 |
| 17 | 0,550 | 0,548 |
| 18 | 0,536 | 0,535 |
| 19 | 0,524 | 0,522 |
| 20 | 0,512 | 0,511 |
| 21 | 0,501 | 0,500 |
| 22 | 0,491 | 0,490 |
| 23 | 0,481 | 0,480 |
| 24 | 0,472 | 0,471 |
| 25 | 0,464 | 0,463 |